Accurate training data is the must-have asset for modern computer vision algorithms. Our training ground truth is captured by a novel light field recording technique. This allows us to provide accurate and dense depth for every image pixel, see image below. This allows much better supervision for depth based computer vision tasks, like monocular depth estimation (depth prediction) or Lidar depth completion.

Using rabbitAI Training Data
This is a small demonstration of the results achievable by using rabbitAI dense GT for training of depth estimation tasks.
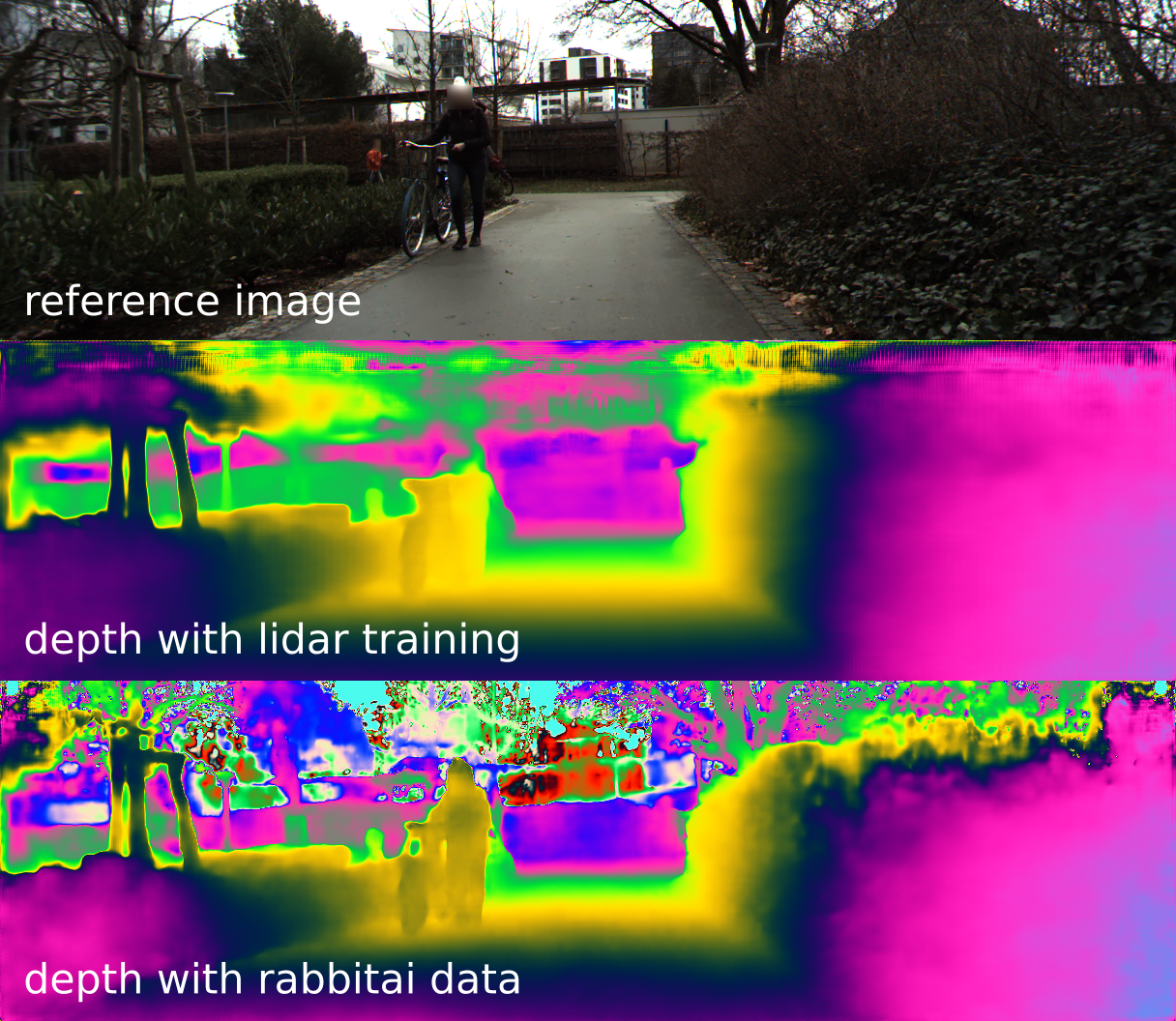
Depth estimation tasks trained with classic Lidar data-sets (in this case KITTI) obtain many errors where Lidar data has gaps. In the image above this is very visible on the upper half of the image. Note that this is not a trivial error which can be ignored, autonomous vehicle must also detect obstacles above the ground (e.g. branches, low hanging signs, protruding loads). Other problematic areas (not shown here) are for example puddles or large shopping windows.
This is Just the Beginning
The results above were achieved by adding 50 of our dense ground truth scenes to an off-the-shelf depth prediction method.
Can you imagine what a large dataset at this quality level can achieve?
We can. Contact us at info@rabbitai.de.